 For the project of automatically assigning topics to the letters to the editor, I needed labeled data. Sometimes blog posts, or articles in a newspaper will have assigned labels (for example, this post is tagged with “machine learning” and “natural language processing”). However, none of the newspapers I got my data from did that. Thus, I needed someone to go through the letters and label them.
For the project of automatically assigning topics to the letters to the editor, I needed labeled data. Sometimes blog posts, or articles in a newspaper will have assigned labels (for example, this post is tagged with “machine learning” and “natural language processing”). However, none of the newspapers I got my data from did that. Thus, I needed someone to go through the letters and label them.
Before tagging the letters, I needed to decide on a list of topics. I went through a small sample of letters, and came up with a pretty comprehensive list that reflected subjects of most current events:
| Politics Healthcare Society Media Community Education Government Environment Legislation | Technology Economy Crime Religion History Military Science Sports Business |
Up until I started labeling, my idea was that each letter would have one main assigned topic. However, I quickly discovered that that might turn to be problematic, as this letter illustrates:
Very soon, Congress will be looking at a new version of the American Health Care Act, the “replace” portion of the push to replace the ACA. The so-called “MacArthur amendment” is designed to appease some of the Freedom Caucus by allowing states to waive the community rating provision. This means that while insurers will still have to technically offer insurance to those with pre-existing conditions, they can charge significantly higher rates for them. What this will do in practice is to give the illusion of covering pre- existing conditions, but will price people completely out of the market by charging premiums so high that no one could afford them. Some suggest high risk pools could cover these people, but these pools have proved to be a loser in all 33 states where they existed, losing a total of $2 billion the year before the ACA eliminated them. Tell Reps. Hultgren and Roskam that those with pre-existing conditions must retain the benefits of the ACA.
Which topic would you assign to this letter? Politics, healthcare, legislation? Clearly, all these topics are important in the letter. There were many letters that could fit into more than one category. I allowed for this by tagging each letter with a main topic, and several secondary ones. Thus, we might assign topics such as “Legislation”, “Healthcare” and even “Economy” to the letter above. The best topic for it would probably be “Healthcare reform”, a transient category that exists only for a few weeks when it is relevant. While often we cannot predefine such topics, we can explore them if we use the letters without labels with an unsupervised machine learning algorithm, such as clustering. In this case, topics would have to be discovered from the data.
Also, frequently, the letter would not neatly fit into any of the categories. For example, this letter talks about antibiotics in the food industry, where the author of the letter summarizes his reasons for why antibiotics and animal crowding are not problematic. While it is indirectly related to healthcare, it does not really talk about it. The label I thought was fitting was “Business”. Some new labels would probably have to be created specifically for this letter, such as “Food”.
Now that I had predefined topics and letter data, I had to set up the mechanics of the process. I created a simple web-app that could be used to assign topics and copy the author and title. The app included a frame with the letter and another frame with the labeling options: text fields for the author and title, a drop-down menu for the main topic and checkboxes for the secondary topics. Once a letter was submitted, a new one would be loaded, until all letters were labeled. Here is a screenshot of the app:
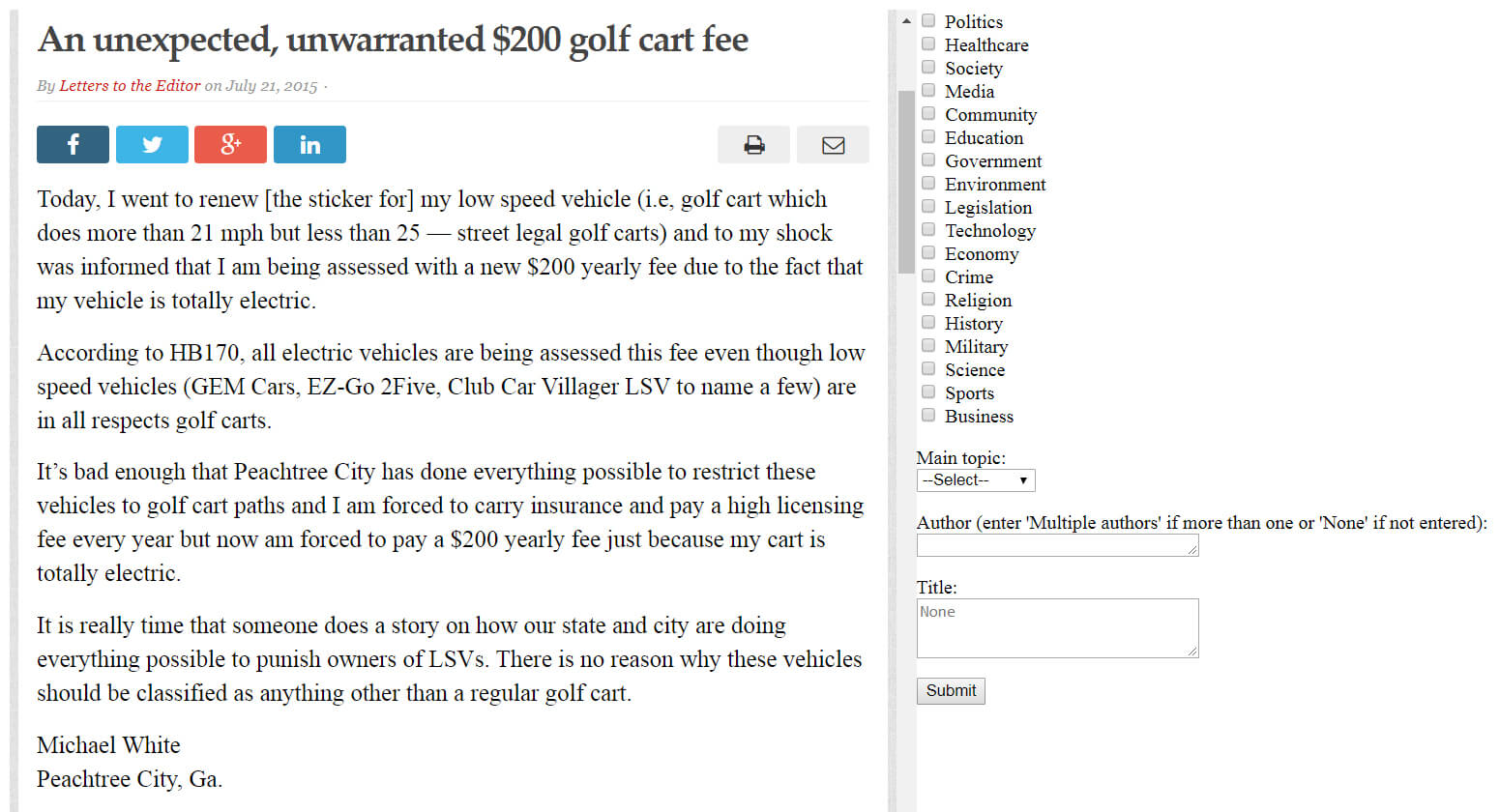
There were around 1600 letters that needed labeling. One option I could have used is a crowdsourcing web-site. I did take a look at some of them, Amazon Mechanical Turk, Fiverr, Onespace and Freelancer. However, I decided against them, since it would add significant time overhead, including quality control of completed work. I labeled all of the 1600 letters myself, which was a very educating experience. Here are some of my takeaways about labeling machine learning data:
- The taggers should be able to add new labels. In case there are several people working on the task, they should coordinate the naming of the new categories.
- Ideally, a team of taggers would label the letters, where the final label would be assigned by consensus between taggers.
- Any list of topics may be limiting in a task where the items to be labeled are about current or evolving events. Depending on the application, unsupervised methods that cluster the items together are worth considering.
After I labeled all the data, I took a quick look at the topic statistics. Some interesting patterns emerged; read about it in the next post.

I agree with you: I would never outsource labeling. Prodi.gy is a potential solution (but the guys from Spacy). We use a simple Excel tool with green and red buttons (for binary classification) to keep the cognitive load as low as possible.
I think parts of labeling could be outsourced, but with much caution. First the data scientist working on the problem needs to understand the data thoroughly, and then the domain experts need to label it. Some very simple parts could be then be outsourced to someone you know you can rely on.
Cool about prodi.gy, thanks for the link!